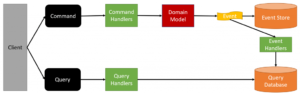
CQRS, which stands for Command Query Responsibility Segregation, is an architectural pattern designed to facilitate the separation of read and write operations in applications. The primary idea behind this pattern is to handle read and write processes as distinct entities, namely ‘Queries’ for reads and ‘Commands’ for writes, and to manage them through individual classes.
CQRS: Command Query Responsibility Segregation
CQRS, short for “Command Query Responsibility Segregation,” represents an architectural approach focused on dividing the responsibilities of commands (saves) and queries (reads) into separate models.
Traditionally, the widely used CRUD pattern (Create-Read-Update-Delete) involves the user interface interacting with a datastore responsible for handling all four operations. However, CQRS proposes a different approach, advocating the splitting of these operations into two distinct models. One model is dedicated to handling queries (referred to as “R”), and the other model manages commands (referred to as “CUD”). By adopting CQRS, we achieve a clear separation between these two types of operations, leading to potential benefits in system design and flexibility.
Please find below the visual representation that explains how this works:
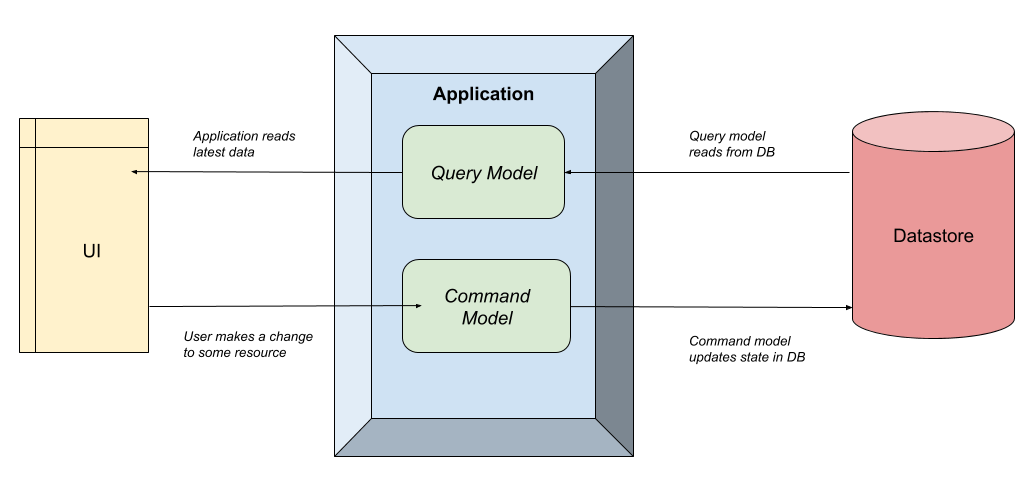
As evident from the illustration, the Application effectively distinguishes the query and command models. The CQRS pattern does not impose any specific formal requirements on how this separation should be implemented. The approach can range from a straightforward separate class within the same application (as demonstrated later with MediatR) to more complex scenarios, such as deploying separate physical applications on different servers. Determining the appropriate approach depends on various factors, including scaling requirements and the existing infrastructure, which are beyond the scope of our discussion today.
The essential takeaway is that establishing a CQRS system revolves around a simple principle: dividing the read operations from the write operations. By adhering to this principle, we can effectively implement the CQRS pattern and leverage its benefits in our application architecture.
What problem does CQRS solve?
The CQRS pattern addresses a common challenge that arises during system design. Typically, when building a system, developers often start by focusing on data storage. They perform actions like database normalization, implement primary and foreign keys to enforce referential integrity, and add indexes, all with the aim of optimizing the “write system.” This approach is common for relational databases like SQL Server or MySQL. Alternatively, in some cases, developers prioritize the read use cases first and then attempt to fit them into a database, giving less consideration to concerns like duplication or other relational database considerations. In these scenarios, “document databases” are often chosen to accommodate these patterns.
Both of these approaches have their merits and are not inherently wrong. However, a fundamental issue arises – it becomes a constant balancing act between optimizing reads and writes, and eventually, one side may dominate. As the development progresses, both aspects need constant analysis, and compromises might have to be made.
CQRS offers a solution to this dilemma by providing the freedom to break away from these constraints. It allows developers to give each system – the read and write systems – equal design and consideration without worrying about the impact on the other system. This approach offers significant advantages in terms of performance and agility, particularly when separate teams are working on these systems. By adopting CQRS, teams can optimize each system independently, leading to better overall performance and a more efficient development process.
Trade-offs:
While CQRS offers significant benefits, like any software approach, it also involves trade-offs that need to be considered. Some of these trade-offs include:
- Management of separate systems (in case of application layer split): Implementing CQRS may require managing separate systems for handling reads and writes. This can introduce additional complexity in terms of deployment, configuration, and coordination between these systems.
- Potential data staleness (in case of database layer split): If the database layer is split to accommodate CQRS, there is a possibility of data becoming stale. As writes and reads are handled separately, there might be a slight delay before the updated data is available for reading. Ensuring data consistency becomes an important consideration in such scenarios.
- Increased complexity in managing multiple components: Adopting CQRS often leads to an increase in the number of components and interactions within the system. This complexity can impact development, maintenance, and troubleshooting efforts.
Ultimately, the decision to use CQRS should be based on specific use cases and requirements. It is crucial to follow good development practices, such as the “keep it simple” (KISS) principle, and only employ patterns like CQRS when there is a genuine need. Premature optimization should be avoided.
In the next section, we will explore a similar pattern called Mediator, which complements the concepts of CQRS.
Mediator Pattern:
The Mediator pattern involves defining an object that encapsulates the interaction logic between multiple objects. Rather than having two or more objects establish direct dependencies on one another, they interact through a central “mediator” object. The mediator acts as a facilitator, responsible for receiving and forwarding these interactions to the appropriate recipients. This decoupling of interactions promotes loose coupling between objects and simplifies the overall system architecture.
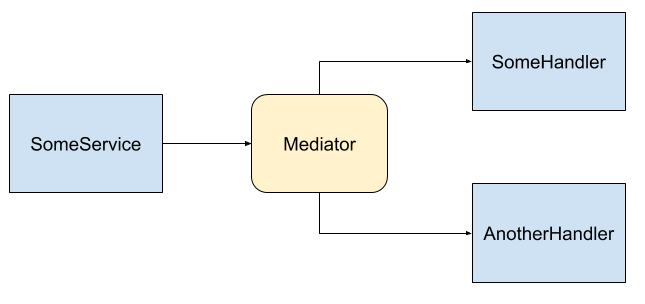
In the depicted image above, a Some Service initiates a message to the Mediator, which, in turn, invokes multiple services to handle the message. Notably, there are no direct dependencies among the blue components.
The Mediator pattern proves valuable for similar reasons as other patterns like Inversion of Control. It facilitates “loose coupling” by minimizing the dependency graph, resulting in simpler and more testable code. When a component has fewer considerations or dependencies, it becomes easier to develop and evolve. As illustrated in the previous image, the services exhibit no direct dependencies, and the message producer remains unaware of the specific handlers or their quantity. This behavior closely resembles the functioning of a message broker in the “publish/subscribe” pattern. Adding another handler becomes seamless without requiring modifications to the message producer.
The Mediator pattern allows for flexibility and extensibility in the system architecture, facilitating the addition or removal of handlers without impacting the producer.
I hope this article come handy.
Please leave a comment if you have any question 🙂
Leave a Reply